
зҡҶгҒ•гӮ“гҒ“гӮ“гҒ«гҒЎгҒҜгҖӮRAPTOR95гҒ§гҒҷгҖӮ
д»ҠеӣһгҒҜж©ҹжў°еӯҰзҝ’гҒЁжҰӮиҰҒгӮ’иӘ¬жҳҺгҒ—гҒҫгҒҷгҖӮ
гҖҖжңҖиҝ‘гҒ§гҒҜгӮҲгҒҸгҖҒгҖҢAIгҖҚгҖҢж©ҹжў°еӯҰзҝ’гҖҚгҖҢгғҮгӮЈгғјгғ—гғ©гғјгғӢгғігӮ°пјҲж·ұеұӨеӯҰзҝ’пјүгҖҚгҒЁгҒ„гҒЈгҒҹиЁҖи‘үгӮ’иҖігҒ«гҒҷгӮӢгҒЁжҖқгҒ„гҒҫгҒҷгҒҢгҖҒгҒ„гҒҫгҒ„гҒЎж„Ҹе‘ігҒ®йҒ•гҒ„гҒҢгӮҸгҒӢгӮҠгҒ«гҒҸгҒ„гҒӢгҒЁжҖқгҒ„гҒҫгҒҷгҖӮеӣі1гҒ«з·ҸеӢҷзңҒгҒ®HPгҒ«гҒӮгӮӢиӘ¬жҳҺгҒ®еӣігӮ’зӨәгҒ—гҒҰгҒ„гҒҫгҒҷгҒҢгҖҒгҒ“гӮҢгӮ’иҰӢгӮӢгҒЁгӮҸгҒӢгӮҠгӮ„гҒҷгҒ„гҒ§гҒҷгҒӯгҖӮж©ҹжў°еӯҰзҝ’гҒҜгғҮгӮЈгғјгғ—гғ©гғјгғӢгғігӮ°гӮ’еҶ…еҢ…гҒ—гҒҰгҒҠгӮҠгҖҒAIгҒҜж©ҹжў°еӯҰзҝ’гӮ’еҶ…еҢ…гҒҷгӮӢй–ўдҝӮжҖ§гҒ«гҒӘгҒЈгҒҰгҒ„гҒҫгҒҷгҖӮAIгҒҜдәәй–“гҒ®жҖқиҖғгӮ’模擬гҒ—гҒҹгғ—гғӯгӮ°гғ©гғ гҒ®гҒ“гҒЁгӮ’жҢҮгҒ—гҖҒгҒӢгҒӘгӮҠеәғзҫ©гҒӘиЁҖи‘үгҒ§гҒҷгҖӮж©ҹжў°еӯҰзҝ’гҒҜз”Ёж„ҸгҒ—гҒҹгғҮгғјгӮҝгҒ§гғўгғҮгғ«гӮ’гғҲгғ¬гғјгғӢгғігӮ°пјҲеӯҰзҝ’пјүгҒҷгӮӢгҒ“гҒЁгҒ«гӮҲгҒЈгҒҰгҖҒеӣһеё°гғ»еҲҶйЎһгғ»гӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҒӘгҒ©гҒ®гӮҝгӮ№гӮҜгӮ’е®ҹиЎҢгҒҷгӮӢгҒ“гҒЁгӮ’иЁҖгҒ„гҒҫгҒҷгҖӮгғҮгӮЈгғјгғ—гғ©гғјгғӢгғігӮ°гҒҜдәәй–“гҒ®зҘһзөҢдјқйҒ”гғўгғҮгғ«гӮ’模擬гҒ—гҒҹгғӢгғҘгғјгғ©гғ«гғҚгғғгғҲгғҜгғјгӮҜгӮ’жҙ»з”ЁгҒ—гҒҹж©ҹжў°еӯҰзҝ’гғўгғҮгғ«гҒ®гҒ“гҒЁгӮ’жҢҮгҒ—гҒҫгҒҷгҖӮи©ізҙ°гҒҜд»ҠеҫҢиӘ¬жҳҺгҒ—гҒҰгҒ„гҒҚгҒҫгҒҷгҒ®гҒ§гҖҒд»ҠеӣһгҒҜгҒ–гҒЈгҒҸгӮҠгҒЁгҒ—гҒҹй–ўдҝӮжҖ§гҒ гҒ‘жҠҠжҸЎгҒ—гҒҰгӮӮгӮүгҒҲгӮҢгҒ°OKгҒ§гҒҷгҖӮ
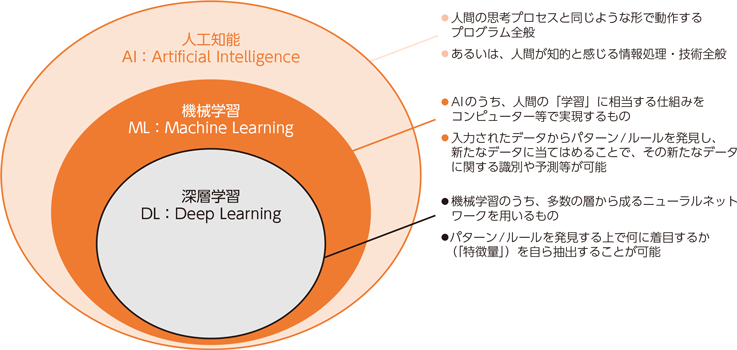
еӣі1гҖҖAIгҖҒж©ҹжў°еӯҰзҝ’гҖҒж·ұеұӨеӯҰзҝ’гҒ®й–ўдҝӮ(еҮәе…ё)з·ҸеӢҷзңҒHP
гҖҖж©ҹжў°еӯҰзҝ’гҒ§е®ҹиЎҢгҒ§гҒҚгӮӢгӮҝгӮ№гӮҜгҒ«гҒӨгҒ„гҒҰгҖҒгӮӮгҒҶе°‘гҒ—ж·ұжҺҳгӮҠгҒ—гҒҰгҒ„гҒҚгҒҫгҒ—гӮҮгҒҶгҖӮж©ҹжў°еӯҰзҝ’гҒ§гҒ§гҒҚгӮӢгӮҝгӮ№гӮҜгҒҜеӨ§гҒҚгҒҸ4гҒӨгҒ«еҲҶйЎһгҒ•гӮҢгҒҫгҒҷгҖӮгҒқгӮҢгҒҜгҖҒгҖҢеӣһеё°гҖҚгҖҢеҲҶйЎһгҖҚгҖҢгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҖҚгҖҢж¬Ўе…ғеүҠжёӣгҖҚгҒ§гҖҒгҒқгҒ®и©ізҙ°гҒҜдёӢиЁҳйҖҡгӮҠгҒ§гҒҷгҖӮ
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
гҖҮеӣһеё°(regression)
еӣһеё°еҲҶжһҗгҒҜгҖҒдёҖгҒӨгҒҫгҒҹгҒҜиӨҮж•°гҒ®зӢ¬з«ӢгҒ—гҒҹеӨүж•°пјҲиӘ¬жҳҺеӨүж•°пјүгҒЁдҫқеӯҳгҒҷгӮӢеӨүж•°пјҲзӣ®зҡ„еӨүж•°пјүгҒЁгҒ®й–ўдҝӮгӮ’гғўгғҮгғ«еҢ–гҒ—гҒҫгҒҷгҖӮгҒ“гҒ®й–ўдҝӮгӮ’йҖҡгҒҳгҒҰгҖҒжңӘзҹҘгҒ®гғҮгғјгӮҝзӮ№гҒ«еҜҫгҒҷгӮӢдәҲжё¬гӮ’иЎҢгҒ„гҒҫгҒҷгҖӮгҒҹгҒЁгҒҲгҒ°гҖҒ家гҒ®гӮөгӮӨгӮәпјҲе№іж–№гғЎгғјгғҲгғ«пјүгҒЁгҒқгҒ®еёӮе ҙдҫЎж јгӮ’й–ўйҖЈд»ҳгҒ‘гӮӢгғўгғҮгғ«гӮ’дҪңжҲҗгҒҷгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгҒҫгҒҷгҖӮгҒ“гҒ“гҒ§гҒҜгҖҒ家гҒ®гӮөгӮӨгӮәгҒҢиӘ¬жҳҺеӨүж•°гҖҒеёӮе ҙдҫЎж јгҒҢзӣ®зҡ„еӨүж•°гҒ«гҒӘгӮҠгҒҫгҒҷгҖӮгҒ“гӮҢгҒ«гӮҲгӮҠгҖҒд»»ж„ҸгҒ®е®¶гҒ®гӮөгӮӨгӮәгҒ«еҹәгҒҘгҒ„гҒҰдҫЎж јгӮ’дәҲжё¬гҒҷгӮӢгҒ“гҒЁгҒҢеҸҜиғҪгҒ«гҒӘгӮҠгҒҫгҒҷгҖӮ
гҖҮеҲҶйЎһ(classification)
зӣ®зҡ„еӨүж•°гҒҢгғ©гғҷгғ«гғҮгғјгӮҝгҒ§гҒӮгӮҠгҖҒиӘ¬жҳҺеӨүж•°XгҒӢгӮүгғ©гғҷгғ«yгӮ’еҮәеҠӣгҒҷгӮӢгғўгғҮгғ«гҒ§гҒҷгҖӮдҫӢгҒҲгҒ°гҖҒз ӮгҒ«еҗ«гҒҫгӮҢгӮӢжҲҗеҲҶ(иӘ¬жҳҺеӨүж•°X)гҒӢгӮүгҖҒгҒ©гҒ“гҒ®ең°еҹҹ(зӣ®зҡ„еӨүж•°y)гҒ§жҺЎеҸ–гҒ•гӮҢгҒҹз ӮгҒӢгӮ’еҮәеҠӣгҒҷгӮӢгғўгғҮгғ«гҒҢеҲҶйЎһгҒ«и©ІеҪ“гҒ—гҒҫгҒҷгҖӮ
гҖҮгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°(clustering)
гӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҒҜгҖҒгғҮгғјгӮҝгғқгӮӨгғігғҲгӮ’дә’гҒ„гҒ«дјјгҒҰгҒ„гӮӢгӮ°гғ«гғјгғ—гҒ«иҮӘеӢ•гҒ§еҲҶйЎһгҒҷгӮӢгғ—гғӯгӮ»гӮ№гҒ§гҒҷгҖӮгҒ“гҒ®еҲҶйЎһгҒҜгҖҒгғҮгғјгӮҝгҒ®зү№еҫҙгҒ«еҹәгҒҘгҒҚгҖҒж•ҷеё«гҒӘгҒ—еӯҰзҝ’пјҲгғ©гғҷгғ«д»ҳгҒ‘гҒ•гӮҢгҒҰгҒ„гҒӘгҒ„гғҮгғјгӮҝгҒӢгӮүгғ‘гӮҝгғјгғігӮ’иҰӢгҒӨгҒ‘еҮәгҒҷжүӢжі•пјүгҒ®дёҖзЁ®гҒЁгҒ—гҒҰиЎҢгӮҸгӮҢгҒҫгҒҷгҖӮгҒҹгҒЁгҒҲгҒ°гҖҒйЎ§е®ўгғҮгғјгӮҝгғҷгғјгӮ№гӮ’еҲҶжһҗгҒ—гҒҰгҖҒйЎһдјјгҒ®иіјиІ·иЎҢеӢ•гӮ’зӨәгҒҷйЎ§е®ўгӮ°гғ«гғјгғ—гӮ’иӯҳеҲҘгҒҷгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгҒҫгҒҷгҖӮгҒ“гӮҢгҒ«гӮҲгӮҠгҖҒгғһгғјгӮұгғҶгӮЈгғігӮ°жҲҰз•ҘгӮ’гӮҲгӮҠеҠ№жһңзҡ„гҒ«гӮ«гӮ№гӮҝгғһгӮӨгӮәгҒҷгӮӢгҒ“гҒЁгҒҢеҸҜиғҪгҒ«гҒӘгӮҠгҒҫгҒҷгҖӮ
гҖҮж¬Ўе…ғеүҠжёӣ(dimensionality reduction)
ж–Үеӯ—йҖҡгӮҠгғҮгғјгӮҝгҒ®ж¬Ўе…ғгӮ’е°ҸгҒ•гҒҸгҒҷгӮӢгҒ“гҒЁгҒ§гҒҷгҖӮ2ж¬Ўе…ғгӮ„3ж¬Ўе…ғзЁӢеәҰгҒ®гғҮгғјгӮҝгҒ§гҒӮгӮҢгҒ°гҖҒгӮ°гғ©гғ•гӮ’дҪңгҒЈгҒҰз°ЎеҚҳгҒ«еӨүж•°й–“гҒ®й–ўдҝӮжҖ§гӮ’жҠҠжҸЎгҒҷгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгҒҫгҒҷгҖӮгҒ—гҒӢгҒ—гҖҒе®ҹйҡӣгҒ«гҒҜ10ж¬Ўе…ғгӮ„гҒқгӮҢд»ҘдёҠгҒ®гғҮгғјгӮҝгӮ»гғғгғҲгӮӮеӨҡж•°еӯҳеңЁгҒ—гҖҒй–ўдҝӮжҖ§гӮ’жҠҠжҸЎгҒҷгӮӢгҒ“гҒЁгҒҜеӣ°йӣЈгҒ«гҒӘгӮҠгҒҫгҒҷгҒ®гҒ§гҖҒгҒқгӮ“гҒӘе ҙеҗҲгҒ«ж¬Ўе…ғеүҠжёӣгӮ’гҒҷгӮӢгҒЁгҖҒй–ўдҝӮжҖ§гӮ’жҠҠжҸЎгҒ—гӮ„гҒҷгҒҸгҒӘгӮӢгғЎгғӘгғғгғҲгҒҢгҒӮгӮҠгҒҫгҒҷгҖӮ
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
4гҒӨгҒ®гӮҝгӮ№гӮҜгҒ®еҶ…гҖҒеӣі2гҒ«зӨәгҒҷгӮҲгҒҶгҒ«еӣһеё°гҒЁеҲҶйЎһгҒҜж•ҷеё«гҒӮгӮҠеӯҰзҝ’гҒЁе‘јгҒ°гӮҢгҖҒгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҒҜж•ҷеё«гҒӘгҒ—еӯҰзҝ’гҒЁе‘јгҒ°гӮҢгҒҫгҒҷпјҲж¬Ўе…ғеүҠжёӣгҒҜ1гҒӨгҒ®еӣігҒ§иЎЁзҸҫгҒҷгӮӢгҒ®гҒҢйӣЈгҒ—гҒ„гҒ®гҒ§гҖҒж–Үеӯ—гҒ гҒ‘гҒ«гҒ—гҒҰгҒ„гҒҫгҒҷпјүгҖӮж•ҷеё«гҒӮгӮҠгҒЁгҒӘгҒ—гҒ®йҒ•гҒ„гӮ’гҒ–гҒЈгҒҸгӮҠиЁҖгҒҶгҒЁгҖҒзӣ®зҡ„еӨүж•°yгҒҢгҒӮгӮӢгҒӢгҒ©гҒҶгҒӢгҒ§гҒҷгҖӮгҒқгӮӮгҒқгӮӮзӣ®зҡ„еӨүж•°гҒЁгҒҜиҮӘеҲҶгҒҢеҮәеҠӣгҒЁгҒ—гҒҰз”ЁгҒ„гҒҹгҒ„еӨүж•°гҒ®гҒ“гҒЁгӮ’жҢҮгҒ—гҒҫгҒҷгҖӮдҫӢгҒҲгҒ°гҖҒеҗҲжҲҗжқЎд»¶гӮҲгӮҠеҢ–еҗҲзү©гҒ®зү©жҖ§гӮ’еҮәеҠӣгҒ—гҒҹгҒ„е ҙеҗҲгҒ«гҒҜеҢ–еҗҲзү©гҒ®зү©жҖ§гҒҢзӣ®зҡ„еӨүж•°гҒ«гҒӘгӮҠгҒҫгҒҷгҒ—гҖҒзөҗжҷ¶еұӨгӮ’дәҲжё¬гҒ—гҒҹгҒ„гҒӘгӮүзөҗжҷ¶еұӨгҒҢзӣ®зҡ„еӨүж•°гҒ«гҒӘгӮҠгҒҫгҒҷгҖӮгҒҫгҒҹгҖҒжңҖеҲқгҒҜгҖҢеҲҶйЎһгҖҚгҒЁгҖҢгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҖҚгҒҢж··еҗҢгҒ—гҒҢгҒЎгҒӢгҒЁжҖқгҒ„гҒҫгҒҷгҒ®гҒ§гҖҒгҒқгҒ®йҒ•гҒ„гҒ«гҒӨгҒ„гҒҰдҫӢгӮ’жҢҷгҒ’гҒҰиӘ¬жҳҺгҒ—гҒҫгҒҷгҖӮ5е“ҒзЁ®гҒ®гғӘгғігӮҙгҒҢгҒӮгӮӢгҒЁгҒ—гҒҰгҖҒгғӘгғігӮҙгҒ®зү№еҫҙгҒӢгӮүгҒқгҒ®е“ҒзЁ®гӮ’иЁҖгҒ„еҪ“гҒҰгӮӢгҒ®гҒҢеҲҶйЎһгҖҒгғӘгғігӮҙгҒ®зү№еҫҙгҒӢгӮүгҒ„гҒҸгҒӨгҒӢгҒ®гӮҜгғ©гӮ№пјҲ5гҒӨгҒ§гҒӘгҒҸгҒҰгӮӮOKпјүгҒ«еҲҶгҒ‘гӮӢгҒ®гҒҢгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҒ§гҒҷгҖӮгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҒҜгҖҒ5зЁ®гҒ®гғӘгғігӮҙгҒ®дёӯгҒӢгӮүгҖҒе“ҒзЁ®пјЎгҒЁжңҖгӮӮдјјгҒҹзү№еҫҙгӮ’жҢҒгҒӨе“ҒзЁ®гӮ’жҺўгҒҷгҒ“гҒЁгҒҢгҒ§гҒҚгҒҫгҒҷгҖӮ

еӣі2гҖҖж©ҹжў°еӯҰзҝ’гҒ®4гҒӨгҒ®гӮҝгӮ№гӮҜ
пјңж©ҹжў°еӯҰзҝ’гҒ§гҒ§гҒҚгӮӢгҒ“гҒЁпјһ
гҖҖдёҠиЁҳгҒ§ж©ҹжў°еӯҰзҝ’гҒ®гӮҝгӮ№гӮҜгӮ’дҪҝгҒЈгҒҰгҖҒдҪ•гҒҢгҒ§гҒҚгӮӢгҒӢгӮ’иӘ¬жҳҺгҒ—гҒҫгҒ—гӮҮгҒҶгҖӮж©ҹжў°еӯҰзҝ’гҒ§гҒ§гҒҚгӮӢгҒ“гҒЁгҒҜж§ҳгҖ…гҒӮгӮҠгҒҫгҒҷгҒҢгҖҒдё»гҒ«гҖҢдәҲжё¬гҖҚгҖҢеӨүж•°й–“гҒ®й–ўдҝӮжҖ§гҒ®жҠҠжҸЎгҖҚгҒ®2гҒӨгҒҢж©ҹжў°еӯҰзҝ’гҒ§гҒ§гҒҚгӮӢгҒ“гҒЁгҒӢгҒЁжҖқгҒ„гҒҫгҒҷгҖӮ
дәҲжё¬пјҡж©ҹжў°еӯҰзҝ’гҒҜгғҮгғјгӮҝгӮ»гғғгғҲгӮ’дҪҝгҒЈгҒҰиЁ“з·ҙгҒ•гҒӣгӮӢгҒ“гҒЁгҒ§гҖҒиӘ¬жҳҺеӨүж•°гӮ’е…ҘеҠӣгҒ—зӣ®зҡ„еӨүж•°гӮ’еҮәеҠӣгҒҷгӮӢгғўгғҮгғ«гҒ§гҒӮгӮӢгҒЁиӘ¬жҳҺгҒ—гҒҫгҒ—гҒҹгҖӮгҒ“гҒ®еҮәеҠӣгҒ•гӮҢгҒҹзӣ®зҡ„еӨүж•°гҒҜиҰіжё¬еҖӨгҒ§гҒҜгҒӘгҒҸгҖҒгғўгғҮгғ«гҒҢе°ҺеҮәгҒ—гҒҹдәҲжё¬еҖӨгҒ«гҒӘгӮҠгҒҫгҒҷгҒ®гҒ§гҖҒж©ҹжў°еӯҰзҝ’гҒ§гҒҜзөҗжһңгҒ®дәҲжё¬гҒҢеҸҜиғҪгҒ§гҒӮгӮӢгҒЁгҒ„гҒҲгҒҫгҒҷгҖӮгҒҫгҒҹгҖҒгҒ“гҒ®зөҗжһңгӮ’дәҲжё¬гҒ§гҒҚгӮӢжҖ§иіӘгӮ’дҪҝгҒЈгҒҰгҖҒзӣ®зҡ„еӨүж•°гҒҢзӢҷгҒ„гҒЁгҒҷгӮӢеҖӨпјҲгҒӮгӮӢгҒ„гҒҜгғ©гғҷгғ«пјүгҒ«гҒӘгӮӢгӮҲгҒҶгҒӘиӘ¬жҳҺеӨүж•°гҒ®еҖӨгӮ’жҺўзҙўгҒҷгӮӢгҒ®гҒ«гӮӮгҒӨгҒӢгӮҸгӮҢгҖҒгҒ“гӮҢгӮ’йҖҶи§ЈжһҗгҒЁе‘јгӮ“гҒ гӮҠгӮӮгҒ—гҒҫгҒҷгҖӮи©ізҙ°гҒҜгҒҫгҒҹеҲҘйҖ”гғ–гғӯгӮ°гҒ«жӣёгҒҸгҒЁжҖқгҒ„гҒҫгҒҷгҖӮ
еӨүж•°й–“гҒ®й–ўдҝӮжҖ§жҠҠжҸЎпјҡгҒ“гҒЎгӮүгҒҜгҖҒеӯҰзҝ’жёҲгҒҝгғўгғҮгғ«иҮӘдҪ“гӮ’и©ізҙ°гҒ«иӘҝгҒ№гҒҰиӘ¬жҳҺеӨүж•°гҒ®йҮҚиҰҒжҖ§гӮ’жҠҠжҸЎгҒ—гҒҹгӮҠгҖҒгӮҜгғ©гӮ№гӮҝгғӘгғігӮ°гҖҒж¬Ўе…ғеүҠжёӣгӮ’гҒҷгӮӢгҒ“гҒЁгҒ§гғҮгғјгӮҝгӮ»гғғгғҲгҒ®зү№еҫҙгӮ„еӨүж•°й–“гҒ®й–ўдҝӮжҖ§гӮ’зҹҘгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгҒҫгҒҷгҖӮгҒ“гҒ“гҒ§жҠҠжҸЎгҒ§гҒҚгӮӢгҒ®гҒҜгҒӮгҒҸгҒҫгҒ§зӣёй–ўй–ўдҝӮгҒ§гҒҷгҒҢгҖҒгҒқгҒ“гҒӢгӮүйҮҚиҰҒгҒӘиҖғеҜҹгҒ«гҒӨгҒӘгҒҢгӮӢгҒ“гҒЁгӮӮгҒӮгӮӢгҒ®гҒ§гҖҒж©ҹжў°еӯҰзҝ’гӮ’з”ЁгҒ„гҒҰеӨүж•°й–“гҒ®й–ўдҝӮжҖ§гӮ’жҠҠжҸЎгҒҷгӮӢгҒ“гҒЁгҒҜйҮҚиҰҒгҒ«гҒӘгӮҠгҒҫгҒҷгҖӮ
д»ҠеӣһгҒҜйқһеёёгҒ«гҒ–гҒЈгҒҸгӮҠгҒЁж©ҹжў°еӯҰзҝ’гҒ®иӘ¬жҳҺгӮ’гҒ—гҒҰгҒҚгҒҫгҒ—гҒҹгҖӮдёҖиҰӢйӣЈгҒ—гҒқгҒҶгҒ§гҒҷгҒҢгҖҒгӮ„гҒЈгҒҰгҒ„гӮӢгӮҝгӮ№гӮҜиҮӘдҪ“гҒҜзҗҶи§ЈгҒҢйӣЈгҒ—гҒ„гӮӮгҒ®гҒ§гҒҜгҒӮгӮҠгҒҫгҒӣгӮ“гҖӮз§ҒгҒҹгҒЎгӮӮз„Ўж„ҸиӯҳгҒ®гҒҶгҒЎгҒ«гҖҒгҖҢгҒ“гӮ“гҒӘе®ҹйЁ“жқЎд»¶гҒ гҒЁгҖҒгҒ§гҒҚгҒҹеҗҲйҮ‘гҒ®зҶұдјқе°ҺзҺҮгҒҜгҖҮгҖҮW/(mгғ»K)гҒ«гҒӘгӮӢгҒ гӮҚгҒҶгҖҚгҒЁгҒ“гӮҢгҒҫгҒ§гҒ®зөҢйЁ“гҒӢгӮүдәҲжё¬гҒ—гҒӘгҒҢгӮүе®ҹйЁ“гӮ’гҒ—гҒҰгҒ„гӮӢгҒЁжҖқгҒ„гҒҫгҒҷгҒҢгҖҒгӮ„гҒЈгҒҰгҒ„гӮӢгҒ“гҒЁгҒҜеҗҢгҒҳгҒ§гҒҷгҖӮеӨ§йҮҸгҒ®гҒ“гӮҢгҒҫгҒ§гҒ®е®ҹйЁ“зөҗжһңгӮ’еӯҰзҝ’гҒ•гҒӣгҒҰгҖҒе®ҹйЁ“зөҗжһңгӮ’дәҲжё¬гҒ—гҒҰгҒ„гӮӢгҒ®гҒ§гҒҷгҖӮ
гҖҖж©ҹжў°еӯҰзҝ’гҒ«гҒӨгҒ„гҒҰгӮӮгҒҶе°‘гҒ—еӯҰзҝ’гҒ—гҒҹгҒ„гҒЁгҒ„гҒҶж–№гҒҜгҖҒжң¬гғ–гғӯгӮ°гҒ§гӮӮгӮӮгҒҶе°‘гҒ—ж·ұжҺҳгӮҠгҒ—гҒҰи§ЈиӘ¬гҒҷгӮӢдәҲе®ҡгҒ§гҒҷгҒ—гҖҒгҒ»гҒӢгҒ«гӮӮгҒ„гҒ„гғ–гғӯгӮ°гӮ„ж•ҷ科жӣёгҒҢгҒӮгӮҠгҒҫгҒҷгҒ®гҒ§гҖҒгҒқгҒЎгӮүгӮ’еҸӮз…§гҒҸгҒ гҒ•гҒ„гҖӮ